
Nobody – and nothing – is perfect. Anyone who deals with the inner workings of a website knows all too well that bugs are a fact of life. But managing a site that’s used by thousands of people and processes hundreds of bookings in a day means we need to be quick to identify these issues and act on them.
This is something we’ve worked on intensively over the last few years. It’s been a steep learning curve, but we’ve reached a point where we’re able to effectively prioritize and handle issues that come our way in a timely fashion – while, miraculously, also maintaining a work-life balance.
This post outlines the fundamental ways that we put out fires and lay fertile ground for future development.
Perfecting the Release
In the early days of FishingBooker, our product wasn’t stable and we didn’t have a mandatory process for reviewing code before it went live on production. Unsurprisingly, this quickly became an issue.
To be completely honest, we have a lot of trauma from those early days. Back then, our system was really unstable. We simply didn’t have the manpower to ensure quality and stability – we just focused on shipping enough features to have a complete product.
Now that we do have the resources and the team to make sure that things are made and released at high quality, we actually use the trauma from the early days to our advantage.
Once our team grew to about 5 engineers, we introduced code reviews as a mandatory part of feature development. And, as time progressed, we moved from a system with virtually no testing to covering every single deployment with continuous integration, including automatic testing with GitHub Actions, manual QA, and code review.
This is a completely different setup to how it used to be. Now, before anything even reaches a human to review, it needs to pass through Github’s ESLint, PHPUnit, PHPStan, and PHPCodeSniffer Actions. This may sound simple, but it’s a huge leap from the early days’ practice of merging first and asking questions later.
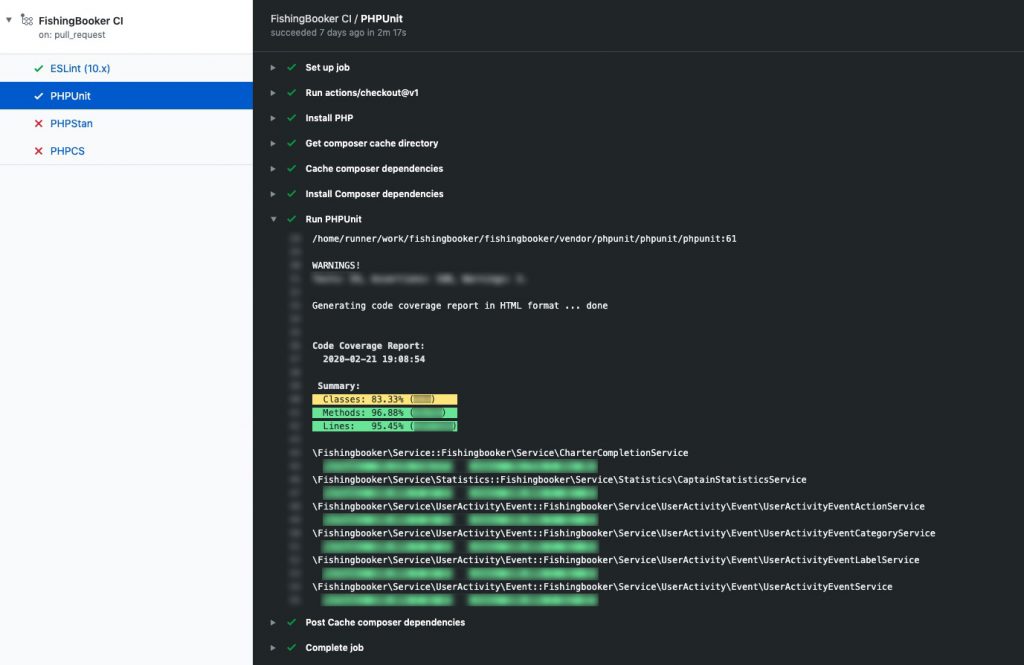
QA is covered by our dedicated testers who look for issues in the user flow, and everyone in the engineering team is involved in code reviews. The process is headed by the team members who have the most in-depth knowledge of FishingBooker’s product, but everyone participates. Who and how much depends on the complexity of the problem and the part of the system that’s being reviewed.
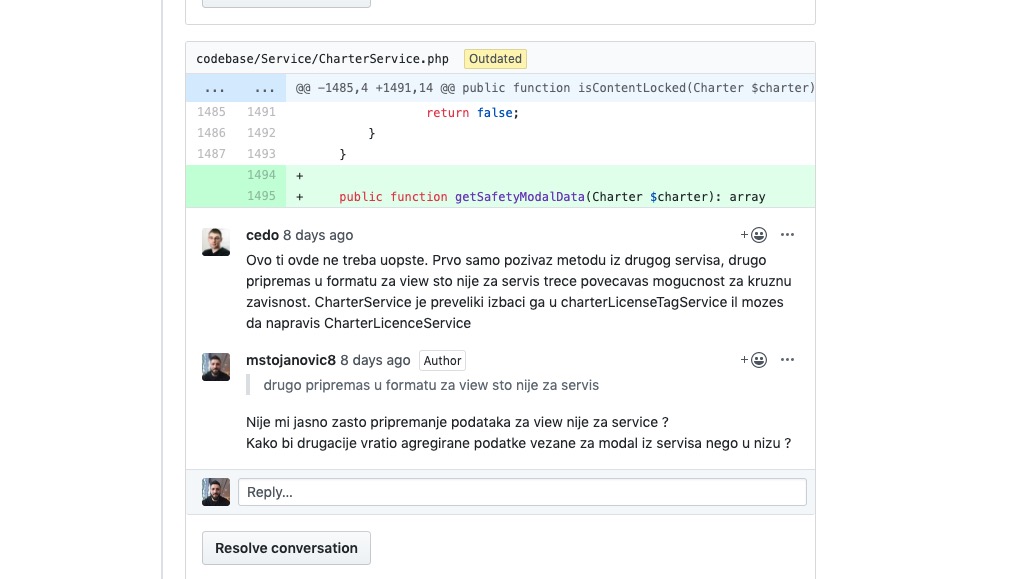
Having everyone involved means that the team’s capacity to review each other’s code is constantly scaling. Regardless of seniority, everyone is able to test out new things that are going onto production, staying familiar with the product as it evolves and continuously learning about different areas of the system.
As well as keeping everyone on board with our ever-growing codebase, this has become a safe space for seniors and juniors alike to challenge how things are done – and then to have that challenge challenged in return! Looking beyond the basic functionalities of new features or bug fixes, the code review process has become cemented into the team’s culture.
Monitoring and On-call
This involvement in reviewing other people’s work empowers everyone to jump into a wide range of projects in any given cycle – and enables them to get involved in fixing whichever problems might come up.
Our dev team operates with a 24/7 rotating on-call schedule, with everyone joining the rotation for one week in every 4-5 weeks. Just like code reviews, this is manned by a mixture of both senior and junior developers: both in order to allow us to react to potential issues as effectively as possible, and to allow our newer team members to master all parts of the product, fast.
As well as allowing people to learn the product effectively, this on-call structure also makes people within the team accountable for creating quality products. As Vukan Simic, FishingBooker’s founder and CEO put it, “Being on the on call rotation gives you that responsibility to make your code work. If you mess it up, the fact that there’s no fixed dev-ops team but that you might be the one whose phone rings in the middle of the night, really gives you that extra responsibility.”
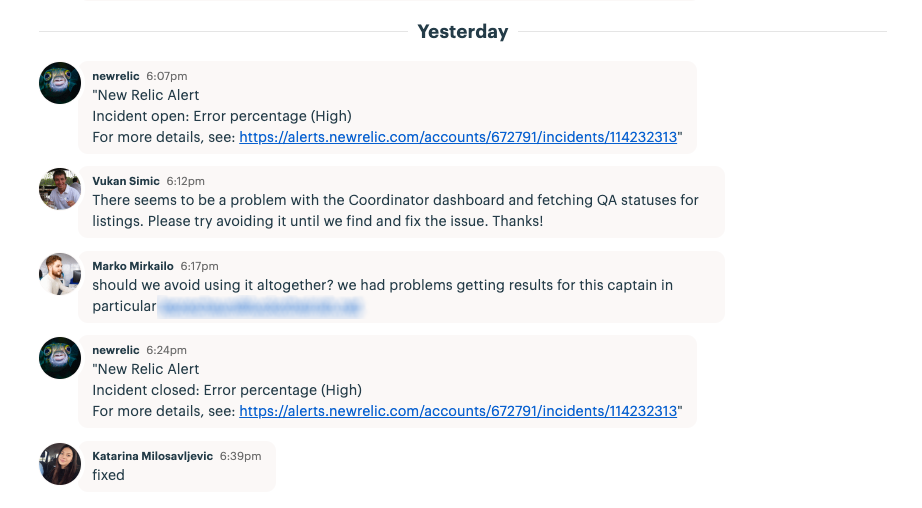
On-call is an important part of our monitoring system, which, like code reviews and testing, has been perfected over the years as we moulded our site into a reliable and stable platform. Using various logs on our servers, auditing user activity, and constant tweaking of alerting policies with New Relic, we’re constantly running automated and semi-automated monitoring processes that our on-call team can keep track of.

Just like code reviews, this comprehensive system emerged as a result of learning the importance of stability the hard way!
In the early days of FishingBooker, a problem on production meant long periods offline and considerable frustration for internal teams and users.
We tackled that by funnelling the data our monitors pick up into New Relic, reaching our on-call team via PagerDuty and setting off a chain reaction.
Then, we swarm the issue. With on-call engineers taking the lead, we try to fix it as quickly as possible. This is followed by a mandatory, publicly shared post mortem on how we fixed it, what the issue was, and how we’ll make sure the issue doesn’t happen again.
And as we integrated our company wide chat tool with New Relic, our customer facing teams also immediately know when there’s a problem – and when it’s been fixed.
Reporting and Bug Fixing
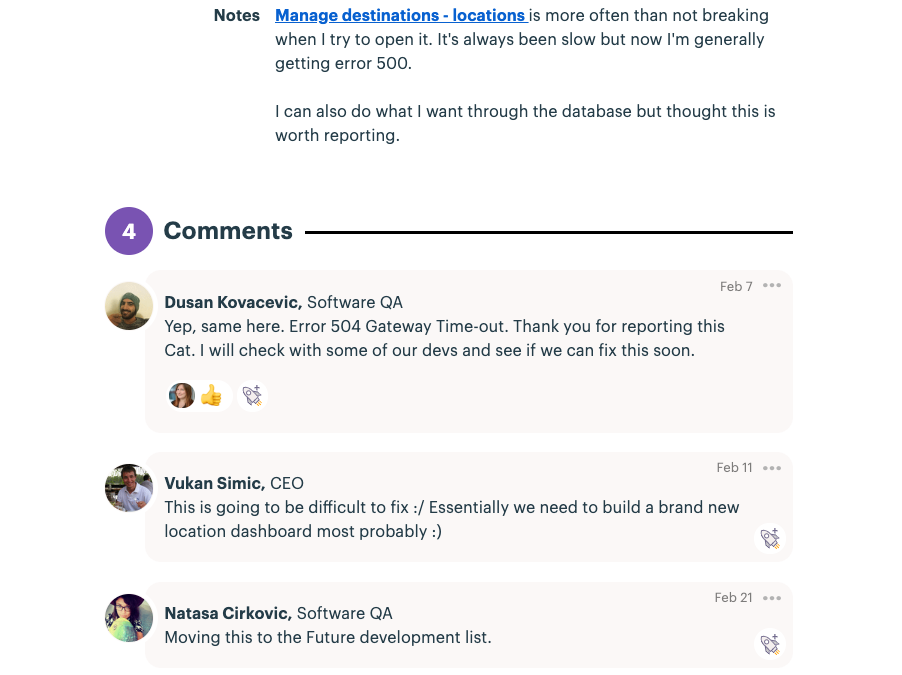
But of course all this doesn’t make us flawless. Once features make it to production, we monitor them closely to keep track of how they’re performing and catch any problems that might occur. We also encourage everyone in the company to report any bugs they find in one centralised place.
Our QA team project manages bugs, prioritising and reacting to them on a daily basis. This is a huge change from our early days, when bugs would pile up and only the most urgent would get seen to – if the engineer wasn’t working on something else at the time.
Once bugs are triaged and reproduced by the QA team, they’re classified according to the section of the product they affect and the priority, and shared with the appropriate engineer. This prioritization system allows us to address critical issues quickly without causing unnecessary loss of attention.
High priority bugs such as issues with payment processing or core infrastructure get fixed right away, while smaller issues get prioritized like any other product work, potentially being included in future release cycles. But, crucially, the person who reported the bug will be informed throughout the process. This means we can set realistic expectations both to them and to any users being affected by the issue.
We still have a lot of ideas for developing our stability practices in the future. But now that we’re in our seventh year of building a platform for booking fishing experiences, we’re happy to have reached a stage where we can sleep soundly before – and after – releases. That is, until the on-call phone rings!